
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 백트래킹
- 반효경교수님
- 가중치없는그래프
- 알고리즘
- 트리
- algorithm
- git
- 그래프
- Mendix
- lcap
- Sort
- 이분탐색
- 자바
- 재귀
- 자료구조
- dfs
- 매개변수 탐색
- Recursion
- 정렬
- 스택
- Bruteforce
- MySQL
- SQL
- 완전탐색
- domain model
- 해시맵
- 프로그래머스
- 멘딕스
- microflow
- 집합
- Today
- Total
mondegreen
자바 ORM 표준 JPA(Java Persistance API)란, 본문
[강의 목표]
1. 객체와 테이블 설계 매핑
1)객체와 테이블을 제대로 설계하고 매핑하는 방법
2) 기본 키와 외래 키 매핑
3) 1:N, N:1, 1:1, N:M 매핑
4) 실무 노하우 + 성능까지 고려
5) 복잡한 시스템도 JPA로 설계할 수 있도록
2. JPA 내부 동작 방식 이해
1) JPA 내부 동작 방식 (그림 + 코드)
2) 어떠한 SQL을 만들어내고 어느 단계에서 실행하는지에 대한 이해
객체 지향 프로그래밍과 관계형 데이터베이스의 패러다임에 차이가 있기 때문에 개발자에게 어려움이 있음
객체 지향 프로그래밍은 추상화, 캡슐화, 정보은닉, 상속, 다형성 등 시스템의 복잡성을 제어할 수 있는 다양한 장치들을 제공한다. 그리고 객체를 RDB나 NoSQL, File 등 다양한 저장소에 영구 보관할 수 있는데 현실적인 대안은 관계형 데이터베이스이다. 그래서 아래와 같은 절차를 개발자가 SQL 매퍼로서 작업하게 된다.

이 과정에서 맞닥뜨리게 되는 것은 다음과 같다.
객체와 관계형 데이터베이스의 차이
1. 상속
2. 연관관계
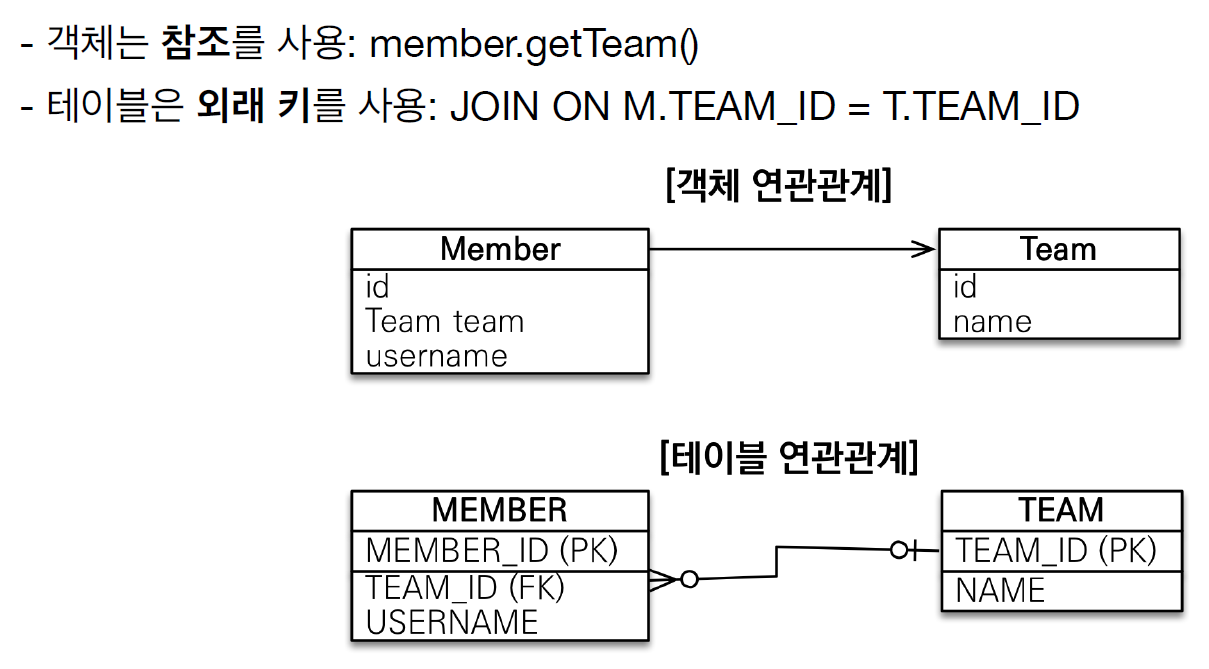
1) 테이블에 맞춰 객체를 설계하는 경우

2) 객체다운 모델링

하지만 위와 같이 객체를 구현하면 DB와 작업 시 매우 번거롭다.
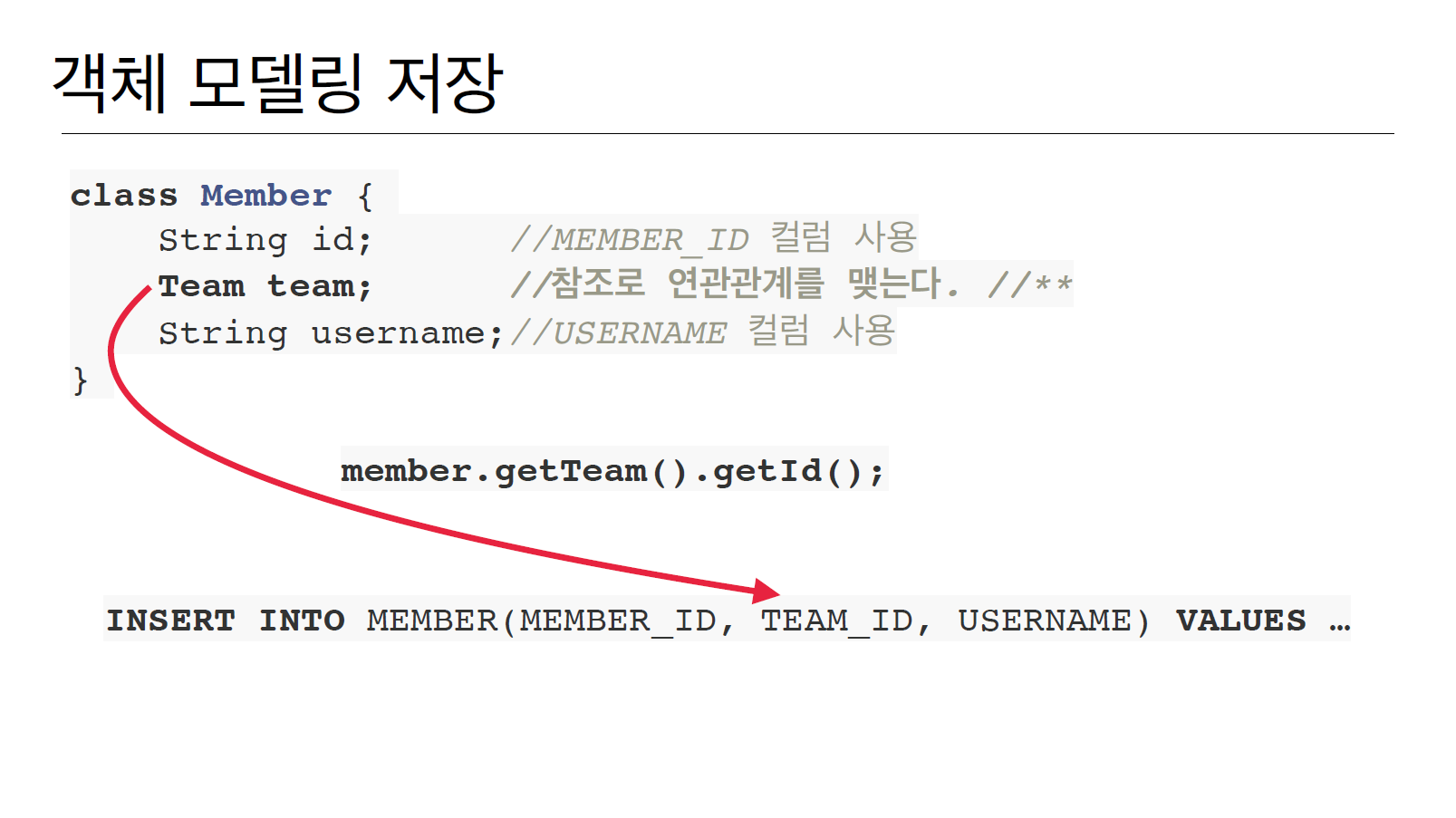
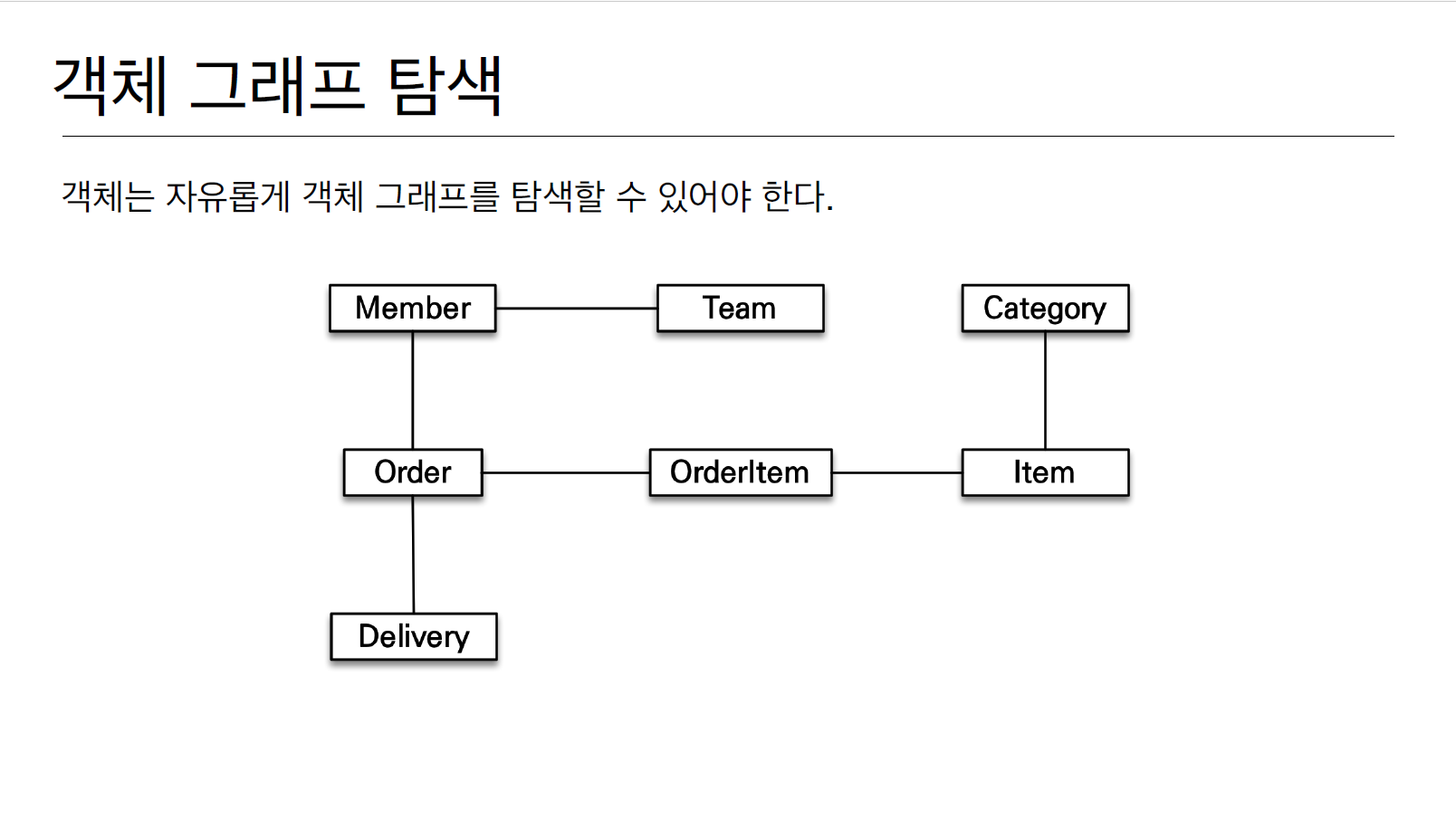
3. 데이터 타입(객체 그래프 탐색)

4. 데이터 식별 방법(비교하기)
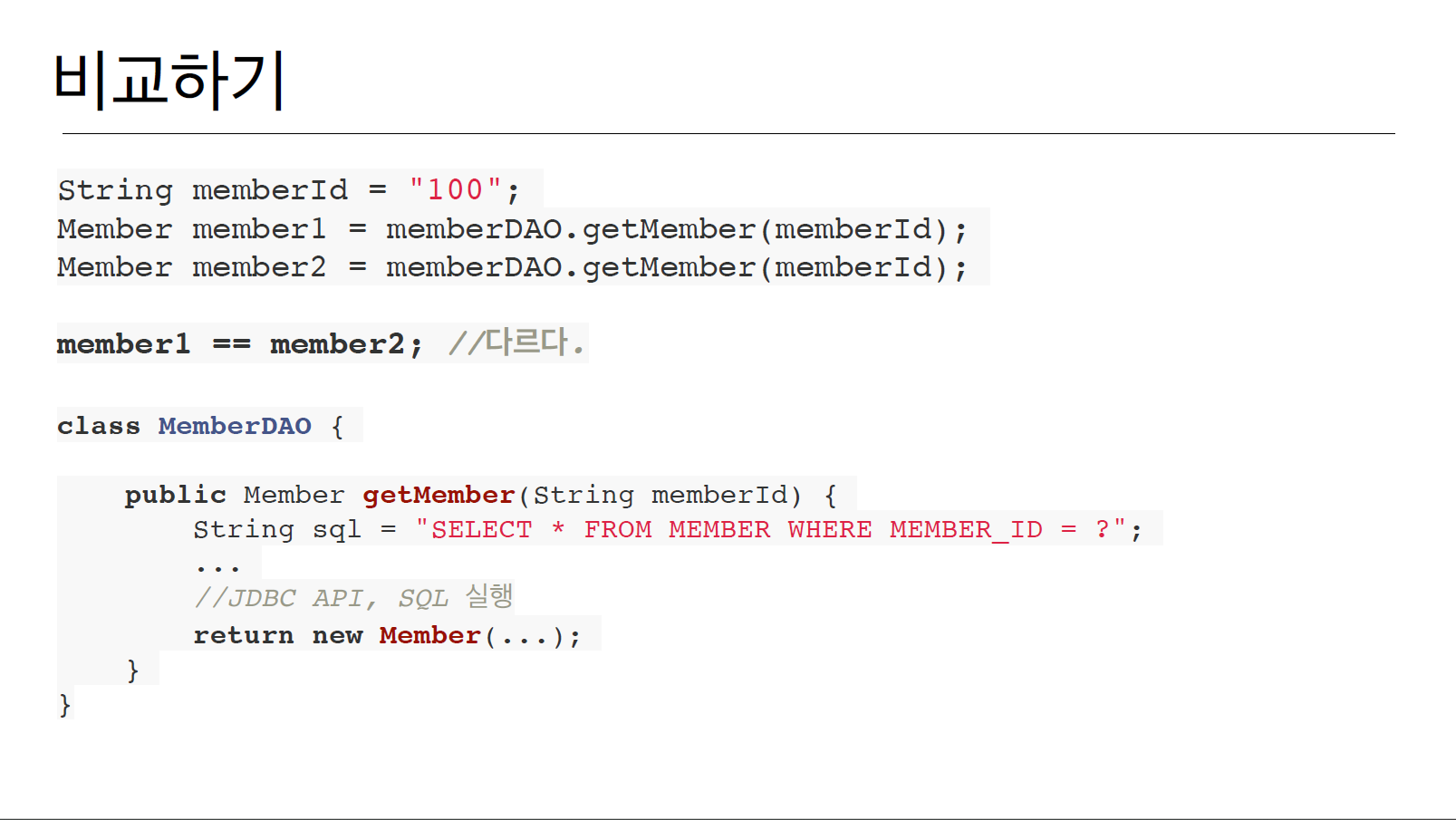

=> 이처럼 객체답게 모델링 할수록 매핑 작업만 증가하게 되었다.
따라서 객체를 자바 컬렉션에 저장하듯이 DB에 저장하는 방법을 고민했고 그 결과 나온 것이 JPA이다.
JPA란,
자바 진영의 ORM 기술 표준으로서, ORM은 Object-Relational Mapping의 약어이다. 즉, 자바의 객체와 데이터베이스의 관계특성을 연결시켜주는 역할을 하는 기술을 의미한다. 이 때 객체는 객체의 특성대로 설계하고 RDBMS는 그 특성 그대로 설계할 수 있고 ORM 프레임워크가 중간에서 매핑해준다.
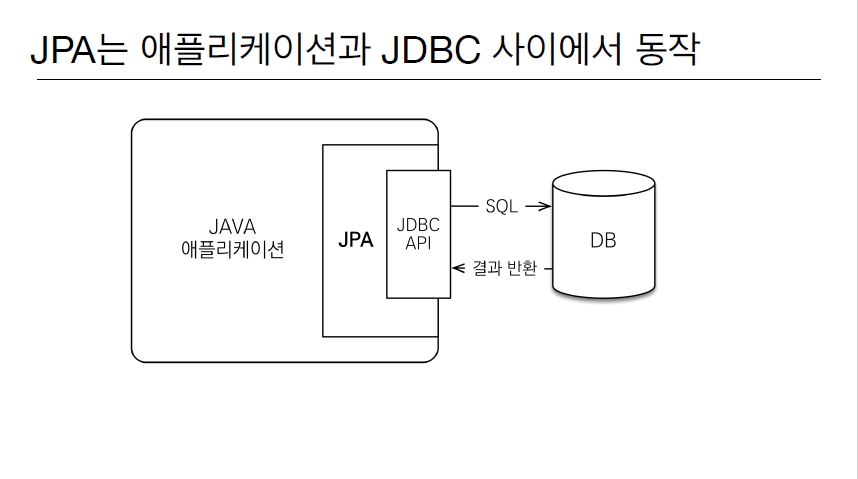
그리고 이 JPA는 인터페이스의 모음이며 JPA를 구현한 3가지 구현체는, 하이버네이트, 이클립스링크, DataNucleus가 있는데 주로 하이버네이트를 사용한다.
참고. 하이버네이트 오픈소스를 개발한 개발자를 영입하여 JPA를 만들었기 때문에 어찌보면 당연한 것일수도...!
그러면 왜 우리는 JPA를 사용해야 하는가
- SQL 중심 개발에서 객체 중심 개발
- 생산성 및 유지보수
- 패러다임 불일치 해결
- 성능 최적화
- 1차 캐시와 동일성 보장(같은 트랜잭션 내에서 같은 엔티티 반환; 즉 SQL 1회 수행)
- 트랜잭션을 지원하는 쓰기 지연(트랜잭션 커밋 전까지 모든 INSERT 모아서 커밋하여 한 번에 전송)
- 지연 로딩/즉시로딩(지연로딩: 객체가 실제 사용될 때 로딩, 즉시로딩: 한번에 연관된 객체까지 미리 조회)
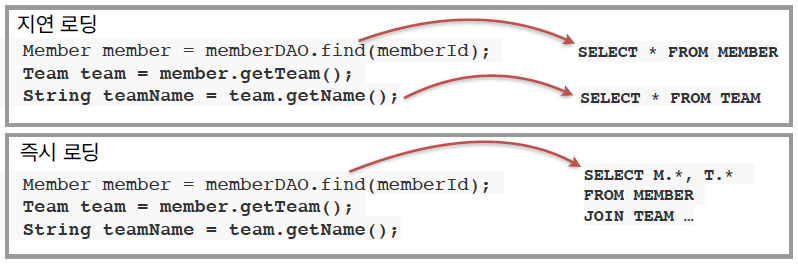
- 데이터 접근 추상화와 벤더 독립성
- 표준
'BackEnd > JPA' 카테고리의 다른 글
| JPA 활용하여 엔티티 설계 시 포함되어야 하는 것(업데이트 중) (0) | 2023.07.26 |
|---|---|
| JPA 프로젝트 생성 (0) | 2023.07.04 |
